Dask
Contents
4.1. Dask#
The content of this section is a Jupyter book implementation of this tutorial.
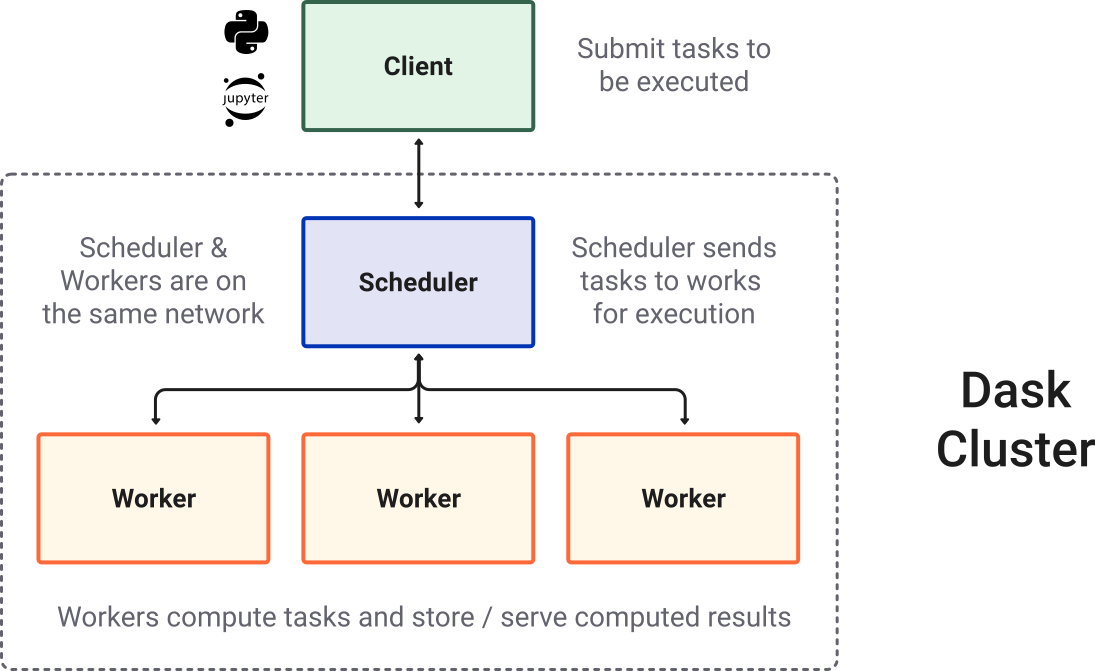
Dask Cluster
4.1.1. Installation#
To install the complete collection of packages offered by Dask:
$ pip install "dask[complete]"
4.1.2. Delayed#
Delayed functions are lazily evaluated functions (i.e. only evaluated when result is required / when compute() is called).
import dask
def inc(x):
return x + 1
@dask.delayed
def add(x, y):
return x + y
Or a function can be passed to the dask.delayed() function.
x = dask.delayed(inc)(1)
y = dask.delayed(inc)(2)
z = add(x,y)
z
Delayed('add-5c9f37b4-2529-4da4-a77f-14a2e477e600')
Because z is still a delayed object, the compute() function needs to be called.
z.compute()
5
The visualize function can be used to visualize the graph.
z.visualize()
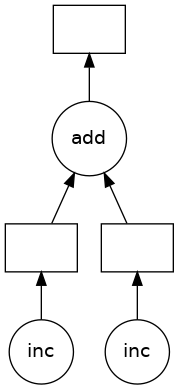
All Dask objects have a dask attribute that stores the calculations necessary to produce the result in a dictionary.
dict(z.dask)
{'add-5c9f37b4-2529-4da4-a77f-14a2e477e600': (<function __main__.add(x, y)>,
'inc-54b1dc7b-e03e-4a4e-8aae-7ab7a3bdbdb0',
'inc-20b11a12-17a4-4e5f-8f59-af75339c9b57'),
'inc-54b1dc7b-e03e-4a4e-8aae-7ab7a3bdbdb0': (<function __main__.inc(x)>, 1),
'inc-20b11a12-17a4-4e5f-8f59-af75339c9b57': (<function __main__.inc(x)>, 2)}
4.1.2.1. Important notes#
Not all functions should be delayed. It may be desirable to immediately execute fast functions which allow us to determine which slow functions need to be called.
Methods and attribute access on delayed objects work automatically, so if you have a delayed object you can perform normal arithmetic, slicing, and method calls on it and it will produce the correct delayed calls.
import numpy as np
x = dask.delayed(np.arange)(10)
y = (x + 1)[::2].sum()
y.compute()
25
4.1.3. Array#
Dask array provides a parallel, larger-than-memory, n-dimensional array using blocked algorithms. Simply put: distributed NumPy.
4.1.3.1. Create dask.array object#
You can create a dask.array Array object with the da.from_array function. This function accepts
data: Any object that supports NumPy slicing
chunks: A chunk size to tell us how to block up our array, like (1000000,)
import dask.array as da
x = np.random.rand(100000000) # create random numpy array
y = da.from_array(x, chunks=(1000000,))
4.1.3.2. Manipulate dask.array objct as you would a np array#
Now that we have an Array we perform standard numpy-style computations like arithmetic, mathematics, slicing, reductions, etc.
y.sum().compute()
49999411.70839054
y[0:4].compute()
array([0.63352681, 0.71011637, 0.88802317, 0.27358411])
4.1.3.3. Limitations#
dask.array does not implement the entire numpy interface. Users expecting this will be disappointed. Notably dask.array has the following failings:
Dask does not implement all of np.linalg. This has been done by a number of excellent BLAS/LAPACK implementations and is the focus of numerous ongoing academic research projects.
dask.arraydoes not support any operation where the resulting shape depends on the values of the array. In order to form the Dask graph we must be able to infer the shape of the array before actually executing the operation. This precludes operations like indexing one Dask array with another or operations like np.where.dask.arraydoes not attempt operations like sort which are notoriously difficult to do in parallel and are of somewhat diminished value on very large data (you rarely actually need a full sort). Often we include parallel-friendly alternatives like topk.Dask development is driven by immediate need, and so many lesser used functions, like np.full_like have not been implemented purely out of laziness. These would make excellent community contributions.
4.1.4. Bag#
Dask-bag excels in processing data that can be represented as a sequence of arbitrary inputs. We’ll refer to this as “messy” data, because it can contain complex nested structures, missing fields, mixtures of data types, etc. The functional programming style fits very nicely with standard Python iteration, such as can be found in the itertools module.
4.1.4.1. Creation#
Dask bags can be created from a Python sequence, file, etc.
import dask.bag as db
b = db.from_sequence([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], npartitions=2)
b.take(3)
(1, 2, 3)
4.1.4.2. Manipulation#
Bag objects hold the standard functional API found in projects like the Python standard library, toolz, or pyspark, including map, filter, groupby, etc.
Operations on Bag objects create new bags. Call the compute() method to trigger execution, as we saw for Delayed objects.
def is_even(n):
return n % 2 == 0
b = db.from_sequence([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
c = b.filter(is_even).map(lambda x: x ** 2)
c
dask.bag<lambda, npartitions=10>
c.compute()
[4, 16, 36, 64, 100]
4.1.4.3. GroupBy and FoldBy#
Often we want to group data by some function or key. We can do this either with the groupby method, which is straightforward but forces a full shuffle of the data (expensive) or with the harder-to-use but faster foldby method, which does a streaming combined groupby and reduction.
groupby: Shuffles data so that all items with the same key are in the same key-value pair.foldby: Walks through the data accumulating a result per key.
Note: the full groupby is particularly bad. In actual workloads you would do well to use foldby or switch to DataFrames if possible.
4.1.4.3.1. groupby#
Groupby collects items in your collection so that all items with the same value under some function are collected together into a key-value pair.
b = db.from_sequence(['Alice', 'Bob', 'Charlie', 'Dan', 'Edith', 'Frank'])
b.groupby(len).compute() # names grouped by length
[(7, ['Charlie']), (3, ['Bob', 'Dan']), (5, ['Alice', 'Edith', 'Frank'])]
b = db.from_sequence(list(range(10)))
is_even = lambda x: x % 2
b.groupby(is_even).starmap(lambda k, v: (k, max(v))).compute()
[(0, 8), (1, 9)]
4.1.4.3.2. foldby#
When using foldby you provide:
A key function on which to group elements
A binary operator such as you would pass to reduce that you use to perform reduction per each group
A combine binary operator that can combine the results of two reduce calls on different parts of your dataset.
Your reduction must be associative. It will happen in parallel in each of the partitions of your dataset. Then all of these intermediate results will be combined by the combine binary operator.
b.foldby(is_even, binop=max, combine=max).compute()
[(0, 8), (1, 9)]
4.1.4.4. Limitations#
Bags provide very general computation (any Python function.) This generality comes at cost. Bags have the following known limitations
Bag operations tend to be slower than array/dataframe computations in the same way that Python tends to be slower than NumPy/Pandas
Bag.groupby is slow. You should try to use Bag.foldby if possible. Using Bag.foldby requires more thought. Even better, consider creating a normalised dataframe.
4.1.5. DataFrame#
The dask.dataframe module implements a blocked parallel DataFrame object that mimics a large subset of the Pandas DataFrame. One Dask DataFrame is comprised of many in-memory pandas DataFrames separated along the index. One operation on a Dask DataFrame triggers many pandas operations on the constituent pandas DataFrames in a way that is mindful of potential parallelism and memory constraints.
import dask.dataframe as dd
# Note: datatypes are inferred by reading the first couple of lines
# and may be incorrect and therefore need to be supplied
df = dd.read_csv('trees.csv',
dtype={"Tree": str, "Park Name": str, "x": np.int8, "y": np.int8})
df.head()
| Tree | Park Name | x | y | |
|---|---|---|---|---|
| 0 | 1 | Canada Park | 2 | 3 |
| 1 | 2 | Otter Park | 63 | 21 |
| 2 | 3 | Canada Park | 2 | 25 |
len(df)
3
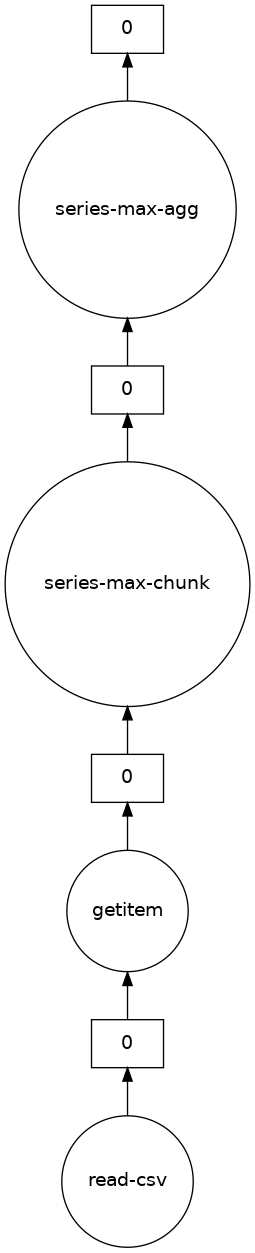
dask.visualize(df.x.max())
4.1.5.1. Limitations#
Dask.dataframe only covers a small but well-used portion of the Pandas API. This limitation is for two reasons:
The Pandas API is huge
Some operations are genuinely hard to do in parallel (e.g. sort)
Additionally, some important operations like set_index work, but are slower than in Pandas because they include substantial shuffling of data, and may write out to disk.